AIによる著作権侵害が問題化していますが、それはイラストや音楽のクリエイティブ作品に限らず、情報や文章にも該当します。その為、ChatGPTにサイトを勝手に学習されたくない、という場合。
ChatGPTの開発元「OpenAI」が公式に発表している、クローリング制限をする方法があります。今回はそちらを紹介いたします。
目次(Tapでジャンプ)
ChatGPTはどこから学習しているのか
Webスクレイピングでクローラーが情報収集を行っている
ChatGPTの学習データは膨大な量が必要ですので、Web上の記事などから「スクレイピング」という手法を用いてクローラー(ロボット)が情報を収集しています。
スクレイピングとは スクレイピングとは、Webサイトのコンテンツの中から特定の情報だけを抽出・取集する技術・行為です。 「ウェブスクレイピング」とも呼ばれています。
https://www.f5.com/
では、そのクローラーがサイトに訪れないようにする方法はあるのでしょうか?
ChatGPTに学習されないようにするには?クローラーのアクセスを禁止するには
https://platform.openai.com/docs/gptbot
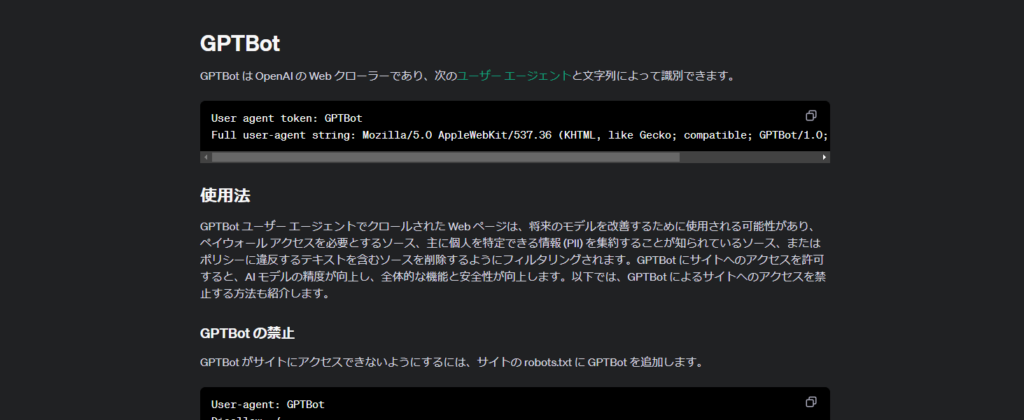
ChatGPTの学習(アクセス)を禁止するには、実はOpenAIが公式に発表している方法があります。
GPTBotのアクセス制限方法(robots.txt使用)
STEP
robots.txtを作成する
User-agent: GPTBot
Disallow: /上記の内容でrobots.txtファイルを作成、もしくは既存のrobots.txtに追記します。
STEP
サイトのルートディレクトリにアップロード
GPTBotにアクセスされたくないサイトのルートディレクトリにアップロードします。これで完了です。
こちらの内容は、サイトのrobots.txt(Webクローラーに対してクロールの指示を行うファイル)に、GPTBotがアクセスしないように指示する事で、GPTBotの学習を防ぐ仕組みです。
ChatGPTから学習を防ぐ、クロールを防止する方法 まとめ
当記事がご参考になりましたら幸いです。